I think I am the last user of blogger. From today I'll write my post to medium.
https://medium.com/@htayyar
Saturday, January 21, 2017
Thursday, July 21, 2016
AdBlock - The browser killer
TLDR; This is not an anti-adblock post. The AdBlock extension is a proved CPU eater and it is proved that the AdBlock extension slows down your browsing experiences. I and many other devs suggest you "Ublock Origin" extension. Ublock Origin is fast and it has less bugs.
We had a CPU usage issue for a while ago with AdBlock users on onedio.com reported by some of our users.
At first we thought that this CPU problem is about user's system resources and we didn't mind too much.
After a while we started to get too many complaints about same issue. We dig into this then we saw that this is a problem about AdBlock extension. Yes the most popular ad-blocker extension in Webstore.
Here is a profile result for onedio.com with a Chrome browser + Adblock extension
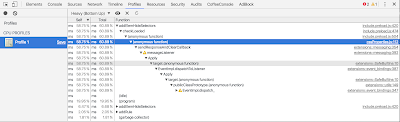
The CPU killer function named addElemHideSelectors is a core function of Adblock. We searched about this function and we saw that this issue has been already reported on AdblockPlus Trac (not Adblock, AdBlock Plus) [1] [2] has been already fixed this by a very few code changes. [3]


But we still didn't solve the CPU issue. We just relaxed our users a little.
It is sad that we should be Adblock compatible.
We then applied the patch that AdblockPlus have made to Adblock. Ad here is the result. The only problem is that Adblock iterating 172K size array without grouping and immediately.
Update #2
After Adblock released it's 3.1 version our pains are gone.

We had a CPU usage issue for a while ago with AdBlock users on onedio.com reported by some of our users.
At first we thought that this CPU problem is about user's system resources and we didn't mind too much.
After a while we started to get too many complaints about same issue. We dig into this then we saw that this is a problem about AdBlock extension. Yes the most popular ad-blocker extension in Webstore.
Here is a profile result for onedio.com with a Chrome browser + Adblock extension

The CPU killer function named addElemHideSelectors is a core function of Adblock. We searched about this function and we saw that this issue has been already reported on AdblockPlus Trac (not Adblock, AdBlock Plus) [1] [2] has been already fixed this by a very few code changes. [3]
So I reported the same issue on https://help.getadblock.com/support/tickets (which is a closed ticket system, where no one sees your ticket or process of the fix.) [4]

Then for long time we got no response. Even an automated response. We dig again and reviewed the Adblock source code. We focused on the problematic function and it's calls. [5]
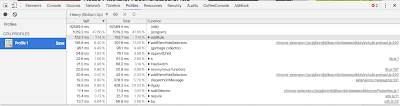
We saw that there is too many array operations while collecting "something" with string match "source" and "track", and we have too many "data-track" and data-tracksource" and "data-source" attributes on our website. So we replaced these attributes with abbreviations like data-trck or data-trcksrc. After this change immediately AdBlock problematic function's CPU usage decreased from %60 to %30. See it from my second CPU profiling result

But we still didn't solve the CPU issue. We just relaxed our users a little.
It is sad that we should be Adblock compatible.
We then applied the patch that AdblockPlus have made to Adblock. Ad here is the result. The only problem is that Adblock iterating 172K size array without grouping and immediately.

Iterating array with groups and using slice instead of splice solves this problem.
"The problem seems to be caused by the while loop inside addElemHideSelectors somehow." noted on AdBlock Plus trac page
As a result we are struggling with AdBlock issues because they have very slow development processes or they develop nothing. If you really want an adblocker extension try Ublock Origin. It is fast. If you want an adblock extension that has "adblock" in it's name try Adblock Plus. But don't use "AdBlock". Popular doesn't mean it's the best.
1. Adblock and AdblockPlus is different projects but they share common libraries.
2. The issue reported on AdblockPlus https://issues.adblockplus.org/ticket/4036#no1
3. Fix for the issue on AdblockPlus repo https://hg.adblockplus.org/adblockpluschrome/rev/9f451f809d40
4. AdBlock ticket system https://help.getadblock.com/support/tickets
5. The js file of AdbBlock that we analyzed https://gist.github.com/hasantayyar/6c5b6139316a9c5e24675bfa89980c4c
Update from my mentions to @getadblocker
5. The js file of AdbBlock that we analyzed https://gist.github.com/hasantayyar/6c5b6139316a9c5e24675bfa89980c4c
Update from my mentions to @getadblocker
@htayyar Sorry we didn't get to your ticket in time! Yes, this is being fixed. AdBlock 3.1 should be 2x faster than AdBlock 3.0.— AdBlock (@getadblock) July 22, 2016
@getadblock just making this small fix makes twice faster - https://t.co/yf7l019juq - btw, is there a predicted date of release?— Hasan Tayyar BEŞİK (@htayyar) July 22, 2016
Update #2
After Adblock released it's 3.1 version our pains are gone.

Sunday, July 3, 2016
How we make decisions at Onedio?
At Onedio.com while we are making decisions we are using natural and primitive methods like our communication that I've mentioned here.

Short answer: We talk, like all we are team leaders. We decide all together. There is no long answer for this. And this is not magic. Try it. It is like deciding what to eat all together. Just make a free and natural office environment that everybody can talk.
If you want some diagram for our decision steps here is an unnecessary diagram.

Other "How we do X at Onedio" posts
- How we overcome monday morning syndrome at Onedio http://tayyar-code.blogspot.com/2016/06/overcome-monday-syndrome-onedio.html
- How we use Slack at Onedio http://tayyar-code.blogspot.com/2016/06/progressive-slack-usage-at-onedio.html
Thursday, June 30, 2016
How we overcome monday morning syndrome at Onedio?
Actually not all of us but some of our fellas found a great way. During the whole Game of Thrones season they schedule a Game of Thrones hour in our office and yes at day time. Now they will start for another TV series.
@cettox said "Every Sunday evening I can't wait for the Monday morning!"
This method is proven and working. Arrange some mutual fun in office at day time for every Monday mornings. It works!
This method is proven and working. Arrange some mutual fun in office at day time for every Monday mornings. It works!
Tuesday, June 28, 2016
Hello Crystal
Crystal Language Goals
- Ruby-inspired syntax.
- Statically type-checked but without having to specify the type of variables or method arguments.
- Be able to call C code by writing bindings to it in Crystal.
- Have compile-time evaluation and generation of code, to avoid boilerplate code.
- Compile to efficient native code.
more on http://crystal-lang.org/
I've started a project with crystal, but I did not contribute for a while.
Just have a look at Crystal. You may like it. Also it has a friendly community.
Progressive Slack Usage at Onedio
TLDR; Slack is just a tool. But it's a great tool. And it is working.
There are too many thoughts about Slack. Some of them are positive [1], some of them are too way negative [2]
At Onedio.com we are a team of hundreds of people. And we are all communicating with Slack. Some of our colleagues use only Slack to do their jobs. We have many webhooks and custom channels, like #daily-reporting-of-somethin, #comment-moderation-channel or #server-status-reports-channel.
We are communicating only with slack. Some of our friends haven't even opened their email inbox.
We have some private channels and we are talking about almost anything in these private channels (side projects, fashion, football, politics, gags, gifs, food, party, gossip, news etc). We have also too many public channels that are open to all users. We like open communication in our company.
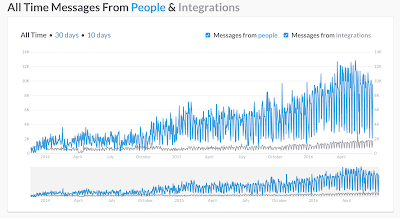
We are not just posting we are also reading messages. Our slack messages are not just noises. We use mentions and magic mentions (@here @group ) wisely.
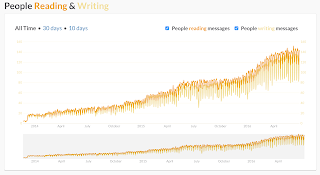


Slack is just a tool. But it's a great tool. And it is working. Again but you will use this tool, and you may use it wrong. Maybe It's all about your communication problem. If your boss sucks at communication, sorry but Slack won't help your communication.
We are using slack as a natural way of communication. Our users are not always online. And sometimes they set their status don't disturb mode. In that case we are using different types of communication methods just like SMS or phone call (Btw slack also has an audio call feature). This is just a simple flow. If you don't like realtime notifications of everything then please use slack channel settings to turn on/off. If you like weekly/daily reports of messages then again use your slack preferences and make your settings with this way. Slack will help you to find your way on natural communication.
Slack works. Slack has a great dev team and all applications are just works without bugs (yes maybe with not very often crashes or UX fails)
Slack has many plugins. You can also write your own service or webhook for slack easily.
I am a fan of IRC and mail lists. But this is different. If your team is very young, dynamic and your project is fast growing, you will need a fast, clean and working method to communicate. Slack is a very advanced version of IRC.
1. Wht Slack Works? https://medium.com/@noelsequeira/slacktivism-cb384450e99e#.k5l2tsagb
2. Slack, I’m Breaking Up with You : https://medium.com/better-people/slack-i-m-breaking-up-with-you-54600ace03ea#.nd5hb27ci
There are too many thoughts about Slack. Some of them are positive [1], some of them are too way negative [2]
At Onedio.com we are a team of hundreds of people. And we are all communicating with Slack. Some of our colleagues use only Slack to do their jobs. We have many webhooks and custom channels, like #daily-reporting-of-somethin, #comment-moderation-channel or #server-status-reports-channel.
We are communicating only with slack. Some of our friends haven't even opened their email inbox.
We have some private channels and we are talking about almost anything in these private channels (side projects, fashion, football, politics, gags, gifs, food, party, gossip, news etc). We have also too many public channels that are open to all users. We like open communication in our company.

Our slack usage increases by time.



Slack is super fast while transferring files.

Slack is just a tool. But it's a great tool. And it is working. Again but you will use this tool, and you may use it wrong. Maybe It's all about your communication problem. If your boss sucks at communication, sorry but Slack won't help your communication.
We are using slack as a natural way of communication. Our users are not always online. And sometimes they set their status don't disturb mode. In that case we are using different types of communication methods just like SMS or phone call (Btw slack also has an audio call feature). This is just a simple flow. If you don't like realtime notifications of everything then please use slack channel settings to turn on/off. If you like weekly/daily reports of messages then again use your slack preferences and make your settings with this way. Slack will help you to find your way on natural communication.
Slack works. Slack has a great dev team and all applications are just works without bugs (yes maybe with not very often crashes or UX fails)
Slack has many plugins. You can also write your own service or webhook for slack easily.
I am a fan of IRC and mail lists. But this is different. If your team is very young, dynamic and your project is fast growing, you will need a fast, clean and working method to communicate. Slack is a very advanced version of IRC.
1. Wht Slack Works? https://medium.com/@noelsequeira/slacktivism-cb384450e99e#.k5l2tsagb
2. Slack, I’m Breaking Up with You : https://medium.com/better-people/slack-i-m-breaking-up-with-you-54600ace03ea#.nd5hb27ci
Sunday, January 17, 2016
Multi-threading in JavaScript with ParallelJS
Parallel.js is a simple library for parallel computing in Javascript (in node.js or in the modern web browsers). Paralleljs takes advantage of Web Workers for the web, and child processes for Node.
What is web workers
Web Workers are a mechanism by which a script operation can be made to run in a background thread separate from the main execution thread of a web application. The advantage of this is that laborious processing can be performed in a separate thread, allowing the main (usually the UI) thread to run without being blocked/slowed down.
- https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API
Multi-Threading in JavaScript
Note that, multi-threaded programming is parallel, but parallel programming is not necessarily multi-threaded. Unless the multi-threading occurs on a single core, in which case it is only concurrent.
Parallel.js
ParallelJS provides a great easy to useAPI for web workers with many helpers. A sample usage :
var p = new Parallel([1, 2, 3, 4, 5]);console.log(p.data)
The instance p contains a set of helper methods, for example spawn, map, reduce.
Here is a simple example of map function usage. It returns a Promise with the result. This is not the right solution for multi-threading with parallel.js but only a simple example.
p.map(function (number) {
return number * number;
}).then(function (data) {
console.log(data);
});
Tuesday, January 12, 2016
Install Caffe with GPU support without pain
This is my cheatsheet to install caffe with gpu support on an ubuntu machine.
https://gist.github.com/hasantayyar/1023dbdb01647b0c9559
apt-get update && apt-get install -q -y \ wget \ build-essential \ module-init-tools cd /opt && \ wget http://developer.download.nvidia.com/compute/cuda/7_0/Prod/local_installers/cuda_7.0.28_linux.run && \ chmod +x *.run && \ mkdir nvidia_installers && \ ./cuda_7.0.28_linux.run -extract=`pwd`/nvidia_installers && \ cd nvidia_installers && \ ./NVIDIA-Linux-x86_64-346.46.run -s -N --no-kernel-module && \ ./cuda-linux64-rel-7.0.28-19326674.run -noprompt #ENV LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-7.0/lib64 #ENV PYTHONPATH=/opt/caffe/python #ENV PATH $PATH:/opt/caffe/.build_release/tools apt-get update && apt-get install -y \ bc cmake curl git gcc-4.6 g++-4.6 gcc-4.6-multilib g++-4.6-multilib \ gfortran unzip wget \
libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev \ libboost-all-dev \ libhdf5-serial-dev \ liblmdb-dev libjpeg62 libfreeimage-dev libatlas-base-dev \ pkgconf protobuf-compiler \ python-dev python-pip python-yaml python-numpy # you may not need to change your gcc version # update-alternatives --install /usr/bin/cc cc /usr/bin/gcc-4.6 30 && \ update-alternatives --install /usr/bin/c++ c++ /usr/bin/g++-4.6 30 && \ update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.6 30 && \ update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.6 30 # Allow it to find CUDA libs echo "/usr/local/cuda/lib64" > /etc/ld.so.conf.d/cuda.conf && \ ldconfig # Clone caffe cd /opt && git clone https://github.com/BVLC/caffe.git # you may not need to install glog. but caffe will log warnings until you've glog installed. cd /opt && wget https://google-glog.googlecode.com/files/glog-0.3.3.tar.gz && \ tar zxvf glog-0.3.3.tar.gz && \ cd /opt/glog-0.3.3 && \ ./configure && \ make && \ make install ldconfig cd /opt && \ wget https://github.com/schuhschuh/gflags/archive/master.zip && \ unzip master.zip && \ cd /opt/gflags-master && \ mkdir build && \ cd /opt/gflags-master/build && \ export CXXFLAGS="-fPIC" && \ cmake .. && \ make VERBOSE=1 && make && make install cd /opt/caffe && \ cp Makefile.config.example Makefile.config # echo "CXX := /usr/bin/g++-4.6" >> Makefile.config && sed -i 's/CXX :=/CXX ?=/' Makefile && \ make all -j8 # link caffe-ld-so.conf under /etc/ld.so.conf.d/ ldconfig # you can install pillow from apt python-pil easy_install pillow # You can find apt alternatives for these python deps. cd /opt/caffe/python ; \ for req in $(cat requirements.txt); do pip install $req; done cd /opt/caffe && make py # Done
Monday, January 11, 2016
If You are Dealing with Data, You will Like Anaconda
With Python at its core, Anaconda is a platform for connecting your expertise and curiosity with data to explore and deploy innovative analytic apps that solve challenging problems with ease and agility. Processing multi-workload data analytics – from batch through interactive to real-time – the platform is used for both ad hoc and production deployments. Anaconda is tuned to take advantage of modern computing environments – everything from multi-core servers, to Spark and Hadoop, to GPUs – delivering flexibility and allowing you to maximize your infrastructure investment. All of this plus the key capabilities required of an open source modern analytics platform – spanning advanced analytics, interactive visualizations, governance, security and operational support.

https://www.continuum.io/
- Anaconda Stack
APP
- Notebooks
- Embeddable Dashboards
- Data Services
- Visual Apps
- VIZ
- Plots
- Interactive Viz
- Big Data
- Maps & GIS
- 3D
- Streaming
- Graphs
- Notebooks
- Interactive Exploration
- Visual Programming
- Data IDEs
- DataPrep
- Stats
- ML & Ensembles
- Deep Learning
- Simulation & Optimization
- Geospatial
- Text & NLP
- Video/Image/Audio Mining
- Graph & Network
- Hadoop & Hive
- Spark
- NoSQL
- DW & SOL
- Files & Web Services
- Servers
- Clusters
- GPUs & High End Workstations
Friday, December 25, 2015
Thursday, November 26, 2015
Analyze Your All Network Traffic with Chrome DevTools

Chrome DevTools has a powerful network panel. If you want to analyze your traffic outside the browser kdzwinel/betwixt electron based application will help you.
Installation
# Clone this repository $ git clone https://github.com/kdzwinel/betwixt.git # Go into the repository $ cd betwixt # Install dependencies and run the app $ npm install && npm start
After installation you should configure your traffic to use proxy as localhost:8008

Last month in my git radar
Here some of my starred open source projects for last month.
This month my radar catched too many projects so if you want to take a look as full list my starred repos link is https://github.com/stars/hasantayyar
BurntSushi / fst
Represents large sets and maps compactly with finite state transducers
evancz / elm-architecture-tutorial
How to create modular Elm code that scales nicely with your app
paldepind / functional-frontend-architecture
A functional frontend framework.
This month my radar catched too many projects so if you want to take a look as full list my starred repos link is https://github.com/stars/hasantayyar
BurntSushi / fst
Represents large sets and maps compactly with finite state transducers
evancz / elm-architecture-tutorial
How to create modular Elm code that scales nicely with your app
paldepind / functional-frontend-architecture
A functional frontend framework.
MyScript / myscript-math-web
The easy way to integrate mathematical expressions handwriting recognition in your web app.
kdzwinel / betwixt
⚡Web Debugging Proxy based on Chrome DevTools Network panel.
samyk / magspoof
MagSpoof is a portable device that can spoof/emulate any magnetic stripe or credit card "wirelessly", even on standard mastripe readers.
samyk / usbdriveby
USBdriveby exploits the trust of USB devices by emulating an HID keyboard and mouse, installing a firewall-evading backdoor, and rerouting DNS within seconds of plugging it in
samyk / skyjack
SkyJack is a drone engineered to autonomously seek out, hack, and wirelessly take full control over any other Parrot drones within wireless or flying distance, creating an army of zombie drones under your control.
joyent / node-krill
simple boolean filter language
0x8890 / simulacra
One-way data binding for web applications.
apfeltee / a2mp3
convert (nearly) every type of (audio)file to mp3 in a quick, easy, batch-enabled way!
Newmu / dcgan_code
Deep Convolutional Generative Adversarial Networks
timekit-io / booking-js
Make a beautiful embeddable booking widget in minutes
CacheBrowser / cachebrowser
A proxy-less censorship resistance tool
MrSwitch / hello.js
A Javascript RESTFUL API library for connecting with OAuth2 services, such as Google+ API, Facebook Graph and Windows Live Connect
feross / webtorrent
Streaming torrent client for node & the browser
Microsoft / JSanity
A secure-by-default, performance, cross-browser client-side HTML sanitization library
facebook / graphql
GraphQL is a query language and execution engine tied to any backend service.
nbubna / storeA better way to use localStorage and sessionStorage
bevacqua / woofmark
Barking up the DOM tree. A modular, progressive, and beautiful Markdown and HTML editor
metabase / metabase
The simplest, fastest way to get business intelligence and analytics to everyone in your company
winterbe / java8-tutorial
Modern Java - A Guide to Java 8
bevacqua / es6
ES6 Overview in 350 Bullet Points
DIYgod / APlayer
Wow, such a beautiful html5 music player
karpathy / neuraltalk2
Efficient Image Captioning code in Torch, runs on GPU
google / skflow
Simplified interface for TensorFlow (mimicking Scikit Learn)
The easy way to integrate mathematical expressions handwriting recognition in your web app.
⚡Web Debugging Proxy based on Chrome DevTools Network panel.
samyk / magspoof
MagSpoof is a portable device that can spoof/emulate any magnetic stripe or credit card "wirelessly", even on standard mastripe readers.
samyk / usbdriveby
USBdriveby exploits the trust of USB devices by emulating an HID keyboard and mouse, installing a firewall-evading backdoor, and rerouting DNS within seconds of plugging it in
samyk / skyjack
SkyJack is a drone engineered to autonomously seek out, hack, and wirelessly take full control over any other Parrot drones within wireless or flying distance, creating an army of zombie drones under your control.
joyent / node-krill
simple boolean filter language
0x8890 / simulacra
One-way data binding for web applications.
apfeltee / a2mp3
convert (nearly) every type of (audio)file to mp3 in a quick, easy, batch-enabled way!
Newmu / dcgan_code
Deep Convolutional Generative Adversarial Networks
timekit-io / booking-js
Make a beautiful embeddable booking widget in minutes
CacheBrowser / cachebrowser
A proxy-less censorship resistance tool
MrSwitch / hello.js
A Javascript RESTFUL API library for connecting with OAuth2 services, such as Google+ API, Facebook Graph and Windows Live Connect
feross / webtorrent
Streaming torrent client for node & the browser
Microsoft / JSanity
A secure-by-default, performance, cross-browser client-side HTML sanitization library
facebook / graphql
GraphQL is a query language and execution engine tied to any backend service.
nbubna / storeA better way to use localStorage and sessionStorage
bevacqua / woofmark
Barking up the DOM tree. A modular, progressive, and beautiful Markdown and HTML editor
metabase / metabase
The simplest, fastest way to get business intelligence and analytics to everyone in your company
winterbe / java8-tutorial
Modern Java - A Guide to Java 8
bevacqua / es6
ES6 Overview in 350 Bullet Points
DIYgod / APlayer
Wow, such a beautiful html5 music player
karpathy / neuraltalk2
Efficient Image Captioning code in Torch, runs on GPU
google / skflow
Simplified interface for TensorFlow (mimicking Scikit Learn)
Tuesday, November 24, 2015
GERÇEK YAZILIMCILARA, GERÇEK HACKATHON
|

|

Monday, October 5, 2015
MongoDB New CRUD API
> // the old insert API > db.test.insert({_id: 1}) WriteResult({ "nInserted" : 1 }) > db.test.insert([{_id: 2}, {_id: 3}, {_id: 4}]) BulkWriteResult({ "writeErrors" : [ ], "writeConcernErrors" : [ ], "nInserted" : 3, "nUpserted" : 0, "nMatched" : 0, "nModified" : 0, "nRemoved" : 0, "upserted" : [ ] })
The new API better distinguishes single- and bulk-insert, and returns more useful results:
> // the new CRUD API > db.test2.insertOne({_id: 1}) { "acknowledged" : true, "insertedId" : 1 } > db.test2.insertMany([{_id: 2}, {_id: 3}, {_id: 4}]) { "acknowledged" : true, "insertedIds" : [ 2, 3, 4 ] }
> // the old update API > db.test.update( ... {_id: 1}, ... {$set: {x: 1}}, ... true /* upsert */, ... false /* multi */ ) WriteResult({ "nMatched" : 0, "nUpserted" : 1, "nModified" : 0, "_id" : 1 })
> // the new update API > db.test2.updateOne( ... {_id: 1}, ... {$set: {x: 1}}, ... {upsert: true} ) { "acknowledged" : true, "matchedCount" : 0, "modifiedCount" : 0, "upsertedId" : 1 }
> // the old replace API > db.test.update( ... {_id: 1}, ... {set: {x: 1}} // OOPS!! ) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) > // document was replaced > db.test.findOne() { "_id" : 1, "set" : { "x" : 1 } }
> // the old delete API > db.test.remove({}) // remove EVERYTHING!!
> // the new delete API > db.test2.deleteOne({}) { "acknowledged" : true, "deletedCount" : 1 } > db.test2.deleteMany({}) { "acknowledged" : true, "deletedCount" : 3 }
Read more on
https://www.mongodb.com/blog/post/consistent-crud-api-next-generation-mongodb-drivers
Friday, October 2, 2015
RIP Yahoo Pipes
As of August 30th 2015, users will no longer be able to create new Pipes. The Pipes team will keep the infrastructure running until end of September 30th 2015 in a read-only mode. http://pipes.yqlblog.net/
Pipes announced before that the service will be shut down. Now it's completely dead.
Sunday, August 9, 2015
Starred open source projects on github last month
kpashka / linda
Multi-platform, highly configurable conference bot.
SamVerschueren / dynongo
MongoDB like syntax for DynamoDB
epha / dynamise
The promised DynamoDB client of your dreams
rebar / rebar
Erlang build tool that makes it easy to compile and test Erlang applications, port drivers and releases.
basho / riak_kv
Riak Key/Value Store
klacke / yaws
Yaws webserver
p8952 / bocker
Docker implemented in 100 lines of bash
maurizzzio / greuler
graph theory visualizations
ericelliott / essential-javascript-links
Essential JavaScript website.
nikgraf / belle
Configurable React Components with great UX
ipselon / react-ui-builder
React UI Builder
borisyankov / react-sparklines
Beautiful and expressive Sparklines React component
jonobr1 / two.js
A renderer agnostic two-dimensional drawing api for the web.
octalmage / robotjs
Node.js Desktop Automation.
s-a / iron-node
Debug Node.js code with Google Chrome Developer Tools.
avinassh / rockstar
Makes you a Rockstar C++ Programmer in 2 minutes
hugeinc / styleguide
A tool to make creating and maintaining style guides easy.
watson-developer-cloud / tone-analyzer-nodejs
Sample Node.js Application for the IBM Tone Analyzer Service
PHP-DI / PHP-DI
The dependency injection container for humans
babel / babel-sublime
Syntax definitions for ES6 JavaScript with React JSX extensions.
7shifts / jQueryTimeAutocomplete
jQuery autocomplete plugin that works with times. Works basically the same as Google Calendars time input when you add an event. Example: http://7shifts.com/better-time-drop-downs-jquery-timeautocomplete/
Upload / Up1
Client-side encrypted image host web server
sparkbox / mediaCheck
Control JS with mediaqueries
arendjr / selectivity
Modular and light-weight selection library for jQuery and Zepto.js
KartikTalwar / gmail.js
Gmail JavaScript API
ermouth / jQuery.my
jQuery.my is a plugin that bind form controls with js data structures.
makeusabrew / bootbox
Wrappers for JavaScript alert(), confirm() and other flexible dialogs using Twitter's bootstrap framework
DrBoolean / mostly-adequate-guide
Mostly adequate guide to FP (in javascript)
Multi-platform, highly configurable conference bot.
SamVerschueren / dynongo
MongoDB like syntax for DynamoDB
epha / dynamise
The promised DynamoDB client of your dreams
rebar / rebar
Erlang build tool that makes it easy to compile and test Erlang applications, port drivers and releases.
basho / riak_kv
Riak Key/Value Store
klacke / yaws
Yaws webserver
p8952 / bocker
Docker implemented in 100 lines of bash
maurizzzio / greuler
graph theory visualizations
ericelliott / essential-javascript-links
Essential JavaScript website.
nikgraf / belle
Configurable React Components with great UX
ipselon / react-ui-builder
React UI Builder
borisyankov / react-sparklines
Beautiful and expressive Sparklines React component
jonobr1 / two.js
A renderer agnostic two-dimensional drawing api for the web.
octalmage / robotjs
Node.js Desktop Automation.
s-a / iron-node
Debug Node.js code with Google Chrome Developer Tools.
avinassh / rockstar
Makes you a Rockstar C++ Programmer in 2 minutes
hugeinc / styleguide
A tool to make creating and maintaining style guides easy.
watson-developer-cloud / tone-analyzer-nodejs
Sample Node.js Application for the IBM Tone Analyzer Service
PHP-DI / PHP-DI
The dependency injection container for humans
babel / babel-sublime
Syntax definitions for ES6 JavaScript with React JSX extensions.
7shifts / jQueryTimeAutocomplete
jQuery autocomplete plugin that works with times. Works basically the same as Google Calendars time input when you add an event. Example: http://7shifts.com/better-time-drop-downs-jquery-timeautocomplete/
Upload / Up1
Client-side encrypted image host web server
sparkbox / mediaCheck
Control JS with mediaqueries
arendjr / selectivity
Modular and light-weight selection library for jQuery and Zepto.js
KartikTalwar / gmail.js
Gmail JavaScript API
ermouth / jQuery.my
jQuery.my is a plugin that bind form controls with js data structures.
makeusabrew / bootbox
Wrappers for JavaScript alert(), confirm() and other flexible dialogs using Twitter's bootstrap framework
DrBoolean / mostly-adequate-guide
Mostly adequate guide to FP (in javascript)
install mahout with less pain
$ mkdir mahout
$ cd mahout/
$ svn co http://svn.apache.org/repos/asf/mahout/trunk
$ cd trunk/
$ mvn compile
$ mvn install
#this will take very long time because of tests
# if you dont want to run tests run mvn -DskipTests clean install
# optionally :
$ export MAHOUT_LOCAL=TRUE
$ export MAHOUT_HEAPSIZE=1000
$ cd mahout/
$ svn co http://svn.apache.org/repos/asf/mahout/trunk
$ cd trunk/
$ mvn compile
$ mvn install
#this will take very long time because of tests
# if you dont want to run tests run mvn -DskipTests clean install
# optionally :
$ export MAHOUT_LOCAL=TRUE
$ export MAHOUT_HEAPSIZE=1000
Wednesday, July 22, 2015
Vogels - DynamoDB data mapper for node.js
Check out vogels on github https://github.com/ryanfitz/vogels/
Features
You can configure vogels to automatically add createdAt and updatedAt timestamp attributes when saving and updating a model. updatedAt will only be set when updating a record and will not be set on initial creation of the model.
If you want vogels to handle timestamps, but only want some of them, or want your timestamps to be called something else, you can override each attribute individually:
You can override the table name the model will use.
if you set the tableName to a function, vogels will use the result of the function as the active table to use. Useful for storing time series data.
See more at examples https://github.com/ryanfitz/vogels/tree/master/examples
Read more at https://github.com/ryanfitz/vogels/
Features
- Simplified data modeling and mapping to DynamoDB types
- Advanced chainable apis for query and scan operations
- Data validation
- Autogenerating UUIDs
- Global Secondary Indexes
- Local Secondary Indexes
- Parallel Scans
You can configure vogels to automatically add createdAt and updatedAt timestamp attributes when saving and updating a model. updatedAt will only be set when updating a record and will not be set on initial creation of the model.
var Account = vogels.define('Account', {
hashKey : 'email',
// add the timestamp attributes (updatedAt, createdAt)
timestamps : true,
schema : {
email : Joi.string().email(),
}
});
var Account = vogels.define('Account', {
hashKey : 'email',
// enable timestamps support
timestamps : true,
// I don't want createdAt
createdAt: false,
// I want updatedAt to actually be called updateTimestamp
updatedAt: 'updateTimestamp'
schema : {
email : Joi.string().email(),
}
});
var Event = vogels.define('Event', {
hashkey : 'name',
schema : {
name : Joi.string(),
total : Joi.number()
},
tableName: 'deviceEvents'
});
var Event = vogels.define('Event', {
hashkey : 'name',
schema : {
name : Joi.string(),
total : Joi.number()
},
// store monthly event data
tableName: function () {
var d = new Date();
return ['events', d.getFullYear(), d.getMonth() + 1].join('_');
}
});
See more at examples https://github.com/ryanfitz/vogels/tree/master/examples
Read more at https://github.com/ryanfitz/vogels/
Monday, June 29, 2015
Should I work for free?
This chart will help you to make a decision.
http://shouldiworkforfree.com/#no5

This cart is a copyrighted work by Jessica Hische 2011
http://shouldiworkforfree.com/#no5

This cart is a copyrighted work by Jessica Hische 2011
Saturday, June 13, 2015
Image Placeholder Services
Here I listed some of my favorite image placeholder services :
Others
This second list also has many funny services. Have a look
- https://placekitten.com/ - all of your placeholders will be kittens! (Or if you like bears http://placebear.com/)
- http://placehold.it/ - boring placeholders but your draft will be more professional without kittens. You can change format, color, text and size
- http://fakeimg.pl/ - alternative to placehold.it
- http://loremflickr.com/ - Random real photos with given sizes. You can give tags or you can get only black and white photos.
- http://p-hold.com/ - This service has too many features for image placeholding.
- http://dummyimage.com/ - alternative to placehold.it . Thi service has also an interactive placeholder url generator form
- https://placeimg.com/ - You can select categories.
- http://lorempixel.com/ - This service is more popular among others (has no more features from p-hold.com but faster).
This second list also has many funny services. Have a look
- http://placebeard.it/ - Bearded pictures
- http://www.stevensegallery.com/ placeholder images of Steven Segal
- http://www.placecage.com - Nick Cage placeholders
- http://www.fillmurray.com/ - Image holders filled with Bill Murray
- http://www.nicenicejpg.com/ only Vanilla Ice jpgs
Bonus
Http status code image holder service
Subscribe to:
Posts (Atom)